


Популярные задачи:
Итератор (Iterator)
Итератор – паттерн поведения объектов, предоставляющий последовательный доступ ко всем элементам составного объекта, не раскрывая его внутреннего представления.
Известен также под именем Cursor (курсор).
Условия, Задача, Назначение
Повсеместно в коде приложения нам тем или иным способом приходится обходить структуры из нескольких внутренних элементов, представляющих совершенно разные и несопоставимые объекты. В любом случае было бы просто здорово совершать такие «обходы» используя единый, унифицированный интерфейс итераций, чем каждый раз для каждого нового внутреннего элементы добавлять в класс-структуру новые операции «обхода».
Основная изюминка заключается в том, что при этом легко инкапсулируется и сама какая бы то ни была внутренняя структура этого составного объекта: хранятся ли внутренние элементы в базе данных, в файле, либо просто в виде массива как обычно и т.д. – клиентскому коду этого просто не нужно знать, он использует лишь единый интерфейс последовательного доступа.
Мотивация
Составной объект, скажем список, должен предоставлять способ доступа к своим элементам, не раскрывая их внутреннюю структуру. Более того, иногда требуется обходить список по-разному, в зависимости от решаемой задачи. Но вряд ли вы захотите засорять интерфейс класса List операциями для различных вариантов обхода, даже если все их можно предвидеть заранее. Кроме того, иногда нужно, чтобы в один и тот же момент было определено несколько активных обходов списка.Все это позволяет сделать паттерн-итератор. Основная его идея в том, чтобы за доступ к элементам и способ обхода отвечал не сам список, а отдельный объект-итератор. В классе Iterator определен интерфейс для доступа к элементам списка. Объект этого класса отслеживает текущий элемент, то есть он располагает информацией, какие элементы уже посещались.
Например, класс List мог бы предусмотреть класс Listlterator:
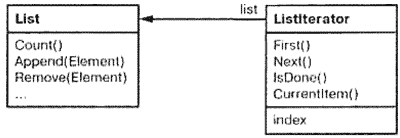
- Для доступа к содержимому агрегированных объектов без раскрытия их внутреннего представления.
- Для поддержки нескольких видов активных обходов одного и того же агрегированного объекта.
- Для предоставления единообразного интерфейса с целью обхода различных агрегированных структур (то есть для поддержки полиморфной итерации).
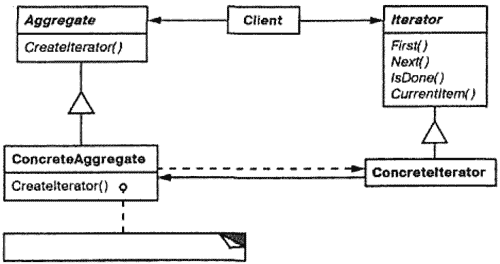
- Iterator – итератор.
Определяет общий интерфейс для доступа и обхода элементов. - Concretelterator - конкретный итератор.
Реализует интерфейс класса Iterator.
Следит (хранит) за текущей позицией при обходе агрегата. - Aggregate – интерфейс фабрике итераторов.
Определяет интерфейс фабрики создания объектов-итераторов. - ConcreteAggregate – конкретная фабрика итераторов.
Реализует интерфейс создания итератора и возвращает экземпляр подходящего класса Concretelterator.
Схема использования паттерна Итератор (Iterator)
Клиент, пользуясь интерфейсом Aggregate, получает итератор Concretelterator для обхода определенного класса списков.Concretelterator отслеживает текущую позицию обхода списка, может возвратить текущий или следующий по порядку элемент, а также может сказать не достигли ли мы конца списка. Пользуясь этими операциями, клиент может проитерировать любой список, предоставляющий свой Concretelterator.
Вопросы, касающиеся реализации паттерна Итератор (Iterator)
Существует множество вариантов реализации итератора. Ниже перечислены наиболее употребительные. Решение о том, какой способ выбрать, часто зависит от управляющих структур, поддерживаемых языком программирования.- Какой участник управляет итерацией.
Важнейший вопрос состоит в том, что управляет итерацией: сам итератор или клиент, который им пользуется.
Если итерацией управляет клиент, то итератор называется внешним, в противном случае - внутренним. Клиенты, применяющие внешний итератор, должны явно запрашивать у итератора следующий элемент, чтобы двигаться дальше по списку (агрегату). Напротив, в случае внутреннего итератора клиент передает итератору некоторую операцию, а итератор уже сам применяет эту операцию к каждому посещенному во время обхода элементу агрегата.
Внешние итераторы обладают большей гибкостью, чем внутренние. Например, сравнить две коллекции на равенство с помощью внешнего итератора очень легко, а с помощью внутреннего - практически невозможно. Слабые стороны внутренних итераторов наиболее отчетливо проявляются в таких языках, как C++, где нет анонимных функций, замыканий (closure) и продолжений (continuation), как в Java, Javascript или Smalltalk. Но, с другой стороны, внутренние итераторы проще в использовании, поскольку они вместо вас реализуют логику обхода. - Что определяет алгоритм обхода.
Алгоритм обхода можно определить не только в итераторе. Его может определить сам список (агрегат) и использовать итератор только для хранения состояния итерации (позиция текущего элемента, признак достижения конца). Такого рода итератор мы называем курсором, поскольку он всего лишь указывает на текущую позицию в агрегате. Клиент вызывает операцию Next агрегата, передавая ей курсор в качестве аргумента. Операция же Next изменяет состояние курсора.
Если за алгоритм обхода отвечает итератор, то для одного и того же списка (агрегата) можно использовать разные алгоритмы итерации, и, кроме того, проще применить один алгоритм к разным агрегатам. С другой стороны, алгоритму обхода может понадобиться доступ к закрытым переменным агрегата. Если это так, то перенос алгоритма в итератор нарушает инкапсуляцию агрегата. - Насколько итератор устойчив.
Модификация агрегата в то время, как совершается его обход, может оказаться опасной. Если при этом добавляются или удаляются элементы, то не исключено, что некоторый элемент будет посещен дважды или вообще ни разу. Простое решение - скопировать агрегат и обходить копию, но обычно это слишком дорого.
Устойчивый итератор (robust) гарантирует, что ни вставки, на удаления не помешают обходу, причем достигается это без копирования агрегата. Есть много способов реализации устойчивых итераторов. В большинстве из них итератор регистрируется в агрегате. При вставке или удалении агрегат либо подправляет внутреннее состояние всех созданных им итераторов, либо организует хранение дополнительной внутренней информации так, чтобы обход выполнялся правильно.
В работе Томаса Кофлера (Thomas Kofler) приводится подробное обсуждение реализации итераторов в каркасе ЕТ++. Роберт Мюррей (Robert Murray) описывает реализацию устойчивых итераторов для класса List из библиотеки USL Standard Components. - Дополнительные операции итератора.
Минимальный интерфейс класса Iterator может состоять из операций First, Next, IsDone и CurrentItem. Этот интерфейс можно и еще уменьшить, если объединить операции Next, IsDone и Currentltem в одну, которая будет переходить к следующему объекту и возвращать его. Если обход завершен, то эта операция вернет специальное значение (например, 0), обозначающее конец итерации.
Но могут оказаться полезными и некоторые дополнительные операции. Например, упорядоченные агрегаты могут предоставлять операцию Previous, позиционирующую итератор на предыдущий элемент. Для отсортированных или индексированных коллекций интерес представляет операция SkipTo, которая позиционирует итератор на объект, удовлетворяющий некоторому критерию. - Использование полиморфных итераторов в C++.
С полиморфными итераторами связаны определенные накладные расходы. Необходимо, чтобы объект-итератор создавался в динамической памяти фабричным методом. Поэтому использовать их стоит только тогда, когда есть необходимость в полиморфизме. В противном случае применяйте конкретные итераторы, которые вполне можно распределять в стеке.
У полиморфных итераторов есть и еще один недостаток: за их удаление отвечает клиент. Здесь открывается большой простор для ошибок, так как очень легко забыть об освобождении распределенного из кучи объекта-итератора после завершения работы с ним. Особенно велика вероятность этого, если у операции есть несколько точек выхода. А в случае возбуждения исключения память, занимаемая объектом-итератором, вообще никогда не будет освобождена.
Эту ситуацию помогает исправить паттерн заместитель. Вместо настоящего итератора мы используем его заместителя, память для которого выделена в стеке. Заместитель уничтожает итератор в своем деструкторе. Поэтому, как только заместитель выходит из области действия, вместе с ним уничтожается и настоящий итератор. Заместитель гарантирует выполнение надлежащей очистки даже при возникновении исключений. Это пример применения хорошо известной в C++ техники, которая называется «выделение ресурса - это инициализация». - Внутренние, скрытые итераторы.
Итератор можно рассматривать как расширение создавший его агрегат. Итератор и агрегат тесно связаны. В C++ такое отношение можно выразить, сделав итератор другом своего агрегата. Тогда не нужно определять в агрегате операции, единственная цель которых - позволить итераторам эффективно выполнить обход, потребуются только создать единственный метод, возвращающий этот самый объект итератора. Однако наличие такого привилегированного доступа может затруднить определение новых способов обхода, так как потребуется изменить интерфейс агрегата, добавив в него нового друга. Для того чтобы решить эту проблему, класс Iterator может включать защищенные операции для доступа к важным, но не являющимся открытыми членам агрегата. Подклассы класса Iterator (и только его подклассы) могут воспользоваться этими защищенными операциями для получения привилегированного доступа к агрегату. - Итераторы для составных объектов.
Реализовать внешние агрегаты для рекурсивно агрегированных структур (таких, например, которые возникают в результате применения паттерна компоновщик) может оказаться затруднительно, поскольку описание положения в структуре иногда охватывает несколько уровней вложенности. Поэтому, чтобы отследить позицию текущего объекта, внешний итератор должен хранить путь через составной объект Composite. Иногда проще воспользоваться внутренним итератором.
Он может запомнить текущую позицию, рекурсивно вызывая себя самого, так что путь будет неявно храниться в стеке вызовов.
Если узлы составного объекта Composite имеют интерфейс для перемещения от узла к его братьям, родителям и потомкам, то лучшее решение дает итератор курсорного типа. Курсору нужно следить только за текущим узлом, а для обхода составного объекта он может положиться на интерфейс этого узла.
Составные объекты часто нужно обходить несколькими способами. Самые распространенные - это обход в прямом, обратном и внутреннем порядке, а также обход в ширину. Каждый вид обхода можно поддержать отдельным итератором. - Пустые итераторы.
Пустой итератор NullIterator - это вырожденный итератор, полезный при обработке граничных условий. По определению, NullIterator всегда считает, что обход завершен, то есть его операция IsDone неизменно возвращает истину. Применение пустого итератора может упростить обход древовидных структур (например, объектов Composite). В каждой точке обхода мы только лишь запрашиваем у текущего элемента итератор для его потомков, не проверяя есть ли у него потомки. Элементы-агрегаты, как обычно, возвращают конкретный итератор. Но листовые элементы возвращают экземпляр NullIterator. Это позволяет реализовать обход всей структуры единообразно.
- Поддержка различных видов обхода агрегата.
Сложные агрегаты можно обходить по-разному. Например, для генерации кода и семантических проверок нужно обходить деревья синтаксического разбора. Генератор кода может обходить дерево во внутреннем или прямом порядке. Итераторы упрощают изменение алгоритма обхода - достаточно просто заменить один экземпляр итератора другим. Для поддержки новых видов обхода можно определить и подклассы класса Iterator. - Итераторы упрощают интерфейс класса Aggregate.
Наличие интерфейса для обхода в классе Iterator делает излишним дублирование этого интерфейса для каждого класса вида Aggregate. Тем самым интерфейс агрегата упрощается. - Одновременно для данного агрегата может быть активно несколько обходов. Итератор следит за инкапсулированным в нем самом состоянием обхода. Поэтому одновременно разрешается осуществлять несколько обходов агрегата.
Пример
Для демонстрации итератора в языке Java достаточно просто посмотреть на Коллекции, а именно, на единый интерфейс Iterator, на реализацию абстрактного класса AbstractList, его внутреннего класса итератора, возвращаемого операцией iterator(). Каждая коллекция возвращает свой внутренний объект, реализующий интерфейс Iterator, поэтому проблема обхода любых списков(List), множеств (Set), хеш-таблиц (Map) – решается очень просто и совершенно независимо от фактического типа коллекции, т.к. в конце концов мы в любом случае имеем дело с общим интерфейсом Iterator, имеющим всего 3 метода: hasNext(), next() и remove().Известные применения паттерна Итератор (Iterator)
Итераторы широко распространены в объектно-ориентированных системах. В том или ином виде они есть в большинстве библиотек коллекций классов. В языке Java итераторы поддерживаются на уровне ядра языка в виде реализованного фреймворка коллекций (Collections). Там определен единый интерфейс итератора, а каждый тип коллекции (список, множество) инкапсулирует создание итератора своего типа (в виде внутреннего класса), т.е. реализует специальный фабричный метод iterator(), возвращающий реализацию итератора для обхода коллекции данного конкретного типа.Вот пример из библиотеки компонентов Грейди Буча, популярной библиотеки, поддерживающей классы коллекций. В ней имеется реализация очереди фиксированной (ограниченной) и динамически растущей длины (неограниченной). Интерфейс очереди определен в абстрактном классе Queue. Для поддержки полиморфной итерации по очередям с разной реализацией итератор написан с использованием интерфейса абстрактного класса Queue. Преимущество такого подхода очевидно - отсутствует необходимость в фабричном методе, который запрашивал бы у очереди соответствующий ей итератор. Однако, чтобы итератор можно было реализовать эффективно, интерфейс абстрактного класса Queue должен быть мощным.
В языке Smalltalk необязательно определять итераторы так явно. В стандартных классах коллекций (Bag, Set, Dictionary, OrderedCollection, String и т.д.) определен метод do:, выполняющий функции внутреннего итератора, который принимает блок (то есть замыкание). Каждый элемент коллекции привязывается к локальной переменной в блоке, а затем блок выполняется.Smalltalk также включает набор классов Stream, которые поддерживают похожий на итератор интерфейс. ReadStream - это, по существу, класс Iterator и внешний итератор для всех последовательных коллекций. Для непоследовательных коллекций типа Set и Dictionary нет стандартных итераторов.
Полиморфные итераторы и выполняющие очистку заместители находятся в контейнерных классах ЕТ++. Курсороподобные итераторы используются в классах каркаса графических редакторов Unidraw.
В системе ObjectWindows 2.0 имеется иерархия классов итераторов для контейнеров. Контейнеры разных типов можно обходить одним и тем же способом. Синтаксис итераторов в ObjectWindows основан на перегрузке постфиксного оператора инкремента ++ для перехода к следующему элементу.
Родственные паттерны
Компоновщик: итераторы довольно часто применяются для обхода рекурсивных структур, создаваемых компоновщиком.Фабричный метод: полиморфные итераторы поручают фабричным методам инстанцировать подходящие для клиента подклассы класса Iterator.
Итератор может использовать хранитель для сохранения состояния итерации и при этом содержит его внутри себя.
Реализации:
java(7), javascript(1) +добавить1) Итератор на javascript, прототипнаяверсия на javascript, code #557[автор:-]